

Diffusion Models vs GANs: A Technical Deep Dive into the Engines of Generative AI

- Forward Diffusion: An image is progressively corrupted by adding noise at each step, following a pre-defined schedule.
- Reverse Diffusion: A noise-predicting model (often a U-Net) learns to reverse this process, removing noise step by step.
Generative AI, the field of artificial intelligence focused on creating new content, is experiencing a renaissance fueled by remarkable advancements in diffusion models and Generative Adversarial Networks (GANs). Both architectures are powerful tools for synthesising realistic and creative content, but they operate on fundamentally different principles. This comprehensive article explores the inner workings of these models, illuminating their mathematical foundations, architectural nuances, real-world applications, and ethical considerations.
Diffusion Models: A Journey Through Stochastic Creation
Diffusion models, inspired by the physical process of diffusion, have emerged as a formidable force in generative AI. Their unique approach involves gradually adding and removing noise to data, transforming it into a simpler distribution and then meticulously reconstructing it back to its original form.
Mathematical Foundations: From Markov Chains to Score-Based Models
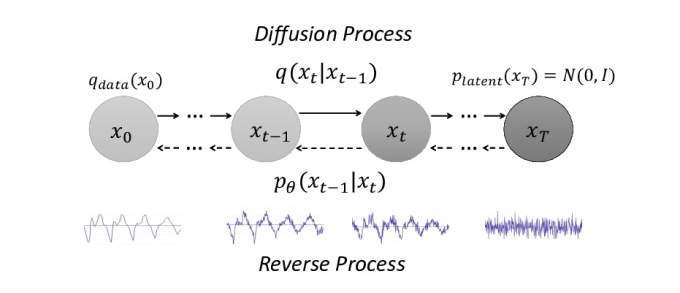
At the heart of diffusion models lies the concept of a Markov chain, a mathematical model where the next state of a system depends solely on its current state. In the forward diffusion process, Gaussian noise is progressively added to the data over a series of discrete steps, following a variance schedule (e.g., linear, cosine) that governs the amount of noise added at each step. This process gradually transforms the data into a standard Gaussian distribution, effectively erasing its original structure.
The reverse diffusion process is where the magic happens. It involves training a neural network model to predict the noise added at each step of the forward process. This model is often formulated as a score-based model, which learns the gradient of the data log-likelihood with respect to the data itself. This gradient, or score function, provides information about how to perturb the noisy data to move it closer to the original data distribution. By iteratively applying this noise-predicting model, starting from pure noise, the original data can be gradually reconstructed.
Architectures: U-Nets and Beyond
Denoising Diffusion Probabilistic Models (DDPMs) are a prominent architecture for diffusion models, leveraging a U-Net structure for the noise-predicting model. The U-Net architecture, originally designed for image segmentation, is well-suited for this task due to its ability to capture both local and global image features through its encoder-decoder structure with skip connections. Recent research has explored alternative architectures like transformers and convolutional neural networks (CNNs) for the noise-predicting model, pushing the boundaries of diffusion models’ capabilities.
Sampling Techniques: Balancing Speed and Quality
Different sampling techniques, such as ancestral sampling and DDIM (Denoising Diffusion Implicit Models), offer varying trade-offs between sample quality and generation speed. Ancestral sampling produces high-quality samples by meticulously following the reverse diffusion process step by step. However, it can be computationally expensive. DDIM, on the other hand, accelerates the generation process by taking larger steps in the denoising trajectory, sacrificing some sample quality for increased speed. Recent research has focused on developing even faster sampling techniques without compromising too much on quality.
Generative Adversarial Networks (GANs): A Creative Battleground
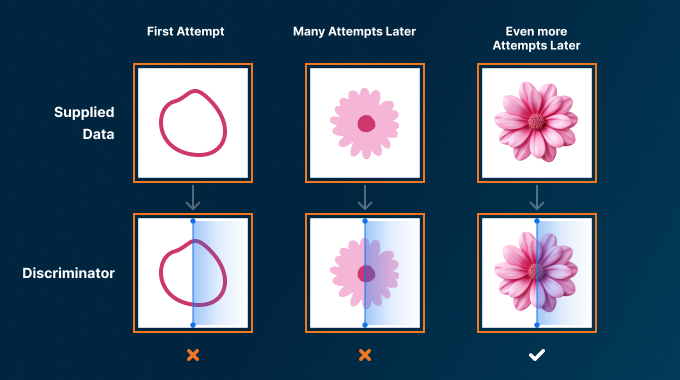
- Generator: Takes random noise as input and tries to generate realistic data.
- Discriminator: Tries to distinguish between real and generated data.
- Adversarial Training: The generator and discriminator compete, pushing each other to improve.
- Mode Collapse: A common issue where the generator produces limited variations of data.
- Wasserstein GAN: A GAN variant using a different distance metric for comparing distributions, addressing mode collapse.
- Spectral Normalisation: A technique to constrain the discriminator’s weights, improving training stability.
GANs, introduced in 2014, are a well-established class of generative models that have revolutionized the field of AI. They operate on a unique adversarial principle, where two neural networks, the generator and the discriminator, engage in a constant battle to outsmart each other.
Architectural Diversity: From DCGANs to Style GANs
The GAN landscape is rich with diverse architectures, each designed to address specific challenges and improve the quality and diversity of generated data. Deep Convolutional GANs (DCGANs) employ convolutional layers to generate images, leveraging their ability to capture spatial hierarchies in data. StyleGANs introduced style-based control, allowing for the manipulation of specific features in generated images, such as pose, expression, and hairstyle. BigGANs, on the other hand, demonstrated the power of scaling up GANs with larger models and datasets, resulting in high-resolution and diverse image generation.
Training Challenges and Solutions: Mode Collapse and Beyond
Training GANs can be a delicate balancing act, with issues like mode collapse and vanishing gradients posing significant challenges. Mode collapse occurs when the generator produces limited variations of data, often getting stuck in a specific mode of the data distribution. Vanishing gradients hinder the generator’s learning process, preventing it from receiving meaningful feedback from the discriminator.
To address these challenges, researchers have developed techniques like Wasserstein GANs and spectral normalization. Wasserstein GANs use a different distance metric, the Wasserstein distance, to compare the real and generated data distributions. This metric is less prone to vanishing gradients and can help mitigate mode collapse. Spectral normalisation constrains the discriminator’s weights, preventing it from becoming too powerful and overwhelming the generator, which can also lead to mode collapse.
Applications: Pioneering Creativity and Innovation
Both diffusion models and GANs have demonstrated remarkable versatility and found applications in a wide range of domains, transforming the way we create, interact with, and understand data.
Diffusion Models in Action:
- Image Synthesis: Diffusion models have revolutionized image synthesis, enabling the generation of photorealistic images, artistic creations in various styles, and even 3D content. They have been used to create stunning landscapes, portraits, and even fictional characters that blur the line between reality and imagination.
- Super-resolution and Image Enhancement: Diffusion models have shown exceptional promise in enhancing the resolution and quality of images. They can upscale low-resolution images to higher resolutions while preserving details and reducing artifacts. They can also be used for image inpainting, filling in missing or damaged parts of an image seamlessly.
- Image Editing and Manipulation: The controllable nature of diffusion models makes them well-suited for image editing and manipulation tasks. They can be used to change the style of an image, add or remove objects, or even modify facial expressions and poses in portraits.
GANs Unleashed:
- Image-to-Image Translation: GANs have excelled in image-to-image translation tasks, where they can transform images from one domain to another. For example, they can convert sketches into photorealistic images, change day scenes to night scenes, or turn horses into zebras.
- Data Augmentation: GANs can be used to generate synthetic data for training machine learning models. This is particularly useful when real data is scarce or expensive to collect. By augmenting training data with GAN-generated samples, models can achieve better performance and generalization.
- Anomaly Detection: GANs can be trained to detect anomalies in data, such as fraudulent transactions or unusual medical scans. The discriminator network, trained on normal data, can learn to identify deviations from the norm, flagging potential anomalies for further investigation.
- Drug Discovery: GANs have shown potential in accelerating drug discovery by generating novel molecules with desired properties. By training on existing drug databases, GANs can generate new molecules that are more likely to be effective and safe.
Ethical Considerations
As the power and capabilities of generative AI continue to grow, it is imperative to address the ethical implications associated with these technologies. The potential for misuse, such as creating deepfakes or generating misleading content, raises concerns about the impact of generative AI on society. Additionally, biases in training data can lead to biased outputs from these models, perpetuating harmful stereotypes and discrimination.
Efforts are underway to develop more transparent and interpretable models, allowing for better understanding of their decision-making processes and mitigating potential biases. The development of robust evaluation metrics and benchmarks for generative models is also crucial for ensuring fairness and accountability. Additionally, there is a growing need for clear guidelines and regulations to govern the use of generative AI and prevent its misuse for malicious purposes.
Conclusion
Diffusion models and GANs represent two powerful and distinct approaches to generative AI, each with its unique strengths and potential. Their ongoing development is pushing the boundaries of what is possible in content creation, paving the way for new forms of artistic expression, scientific discovery, and technological innovation. As we continue to explore the vast landscape of generative AI, it is essential to consider the ethical implications and strive for responsible and equitable use of these powerful tools. The future of generative AI is bright, and with continued research and development, we can expect even more impressive and impactful applications of these models in the years to come.
Frequently Asked Questions (FAQ)
1. What are the main differences between diffusion models and GANs?
Diffusion models generate data by gradually adding and removing noise, while GANs involve a generator and discriminator network competing against each other. Diffusion models are known for producing high-quality images, while GANs are versatile and can be applied to various types of data.
2. What are some common challenges in training GANs?
Common challenges include:
Mode collapse: Limited data variations
Vanishing gradients: Hindered learning process
Non-convergence: Unstable training
Instability: Sensitivity to hyperparameters
3. How are these challenges being addressed?
Techniques like Wasserstein GANs, spectral normalization, gradient penalties, and mini-batch discrimination are used to mitigate these challenges.
4. What are the advantages of diffusion models over GANs?
Diffusion models often produce higher quality and more diverse images and are less prone to mode collapse. However, they can be computationally more expensive.
5. What are the advantages of GANs over diffusion models?
GANs are more versatile and can be applied to various data types. They are also adept at learning and mimicking specific styles. However, they can be more difficult to train and may suffer from mode collapse.
6. What are the potential applications of generative AI in the future?
Generative AI has the potential to revolutionize fields like art, healthcare, entertainment, education, and science.
7. What are the ethical concerns surrounding generative AI?
Ethical concerns include the potential for misuse (e.g., deepfakes), perpetuation of biases, and lack of transparency. The development of ethical guidelines and regulations is crucial to ensure responsible use of this technology.

Director | AI Strategy, Innovation