

Multimodal Generalized Category Discovery: Impact on the Future of Multimodals in Generative AI
The field of Generative AI has already revolutionized industries by automating complex tasks like content creation, language translation, and even scientific discoveries. However, most of these advancements have been confined to single-modal systems—those that rely exclusively on text, images, or sound. This limitation is increasingly being overcome through innovations like Multimodal Generalized Category Discovery (MM-GCD), a groundbreaking framework designed to handle multimodal inputs (text, images, etc.). As introduced by Su et al. in their research paper, MM-GCD bridges the gap between different forms of data to discover and classify known and unknown categories across various modalities. Let’s explore how this technology works, its real-world applications, and the transformative effect it could have on the future of AI.
Understanding MM-GCD: How Does it Work?
At its core, MM-GCD builds upon the concept of Generalized Category Discovery (GCD), which classifies both known and unknown classes in datasets. Traditional GCD frameworks were constrained to unimodal data, such as only images or text. In contrast, MM-GCD handles multiple forms of data simultaneously. It aligns both the feature and output spaces across different modalities (for instance, matching the information from an image with the context from accompanying text), allowing a much richer and accurate classification.
The core challenge MM-GCD addresses is the misalignment of heterogeneous information across modalities. For example, when analyzing an image of a cat paired with a text description like “a playful kitten,” the model must learn to align the information from both sources correctly. MM-GCD uses contrastive learning and knowledge distillation to solve this problem, aligning the features and outputs of both modalities to achieve a richer and more accurate classification.
Evolution of Multimodal Learning
MM-GCD builds on several prior advancements in multimodal learning. Before MM-GCD, most models like CLIP-GCD and SimGCD focused on unimodal tasks, excelling in handling either visual or textual data but missing out on the richness of multimodal information. Su et al. tackle this limitation through innovations in multimodal feature alignment and fusion.
Key Techniques in Multimodal Learning:
- Feature Concatenation: Traditional approaches relied on concatenating features from different modalities. However, this often led to performance degradation as irrelevant or noisy information from one modality could negatively influence the model.
- Contrastive Learning: By aligning related features from different modalities, MM-GCD ensures that features like a dog’s image and a descriptive text are recognized as belonging to the same category.
- Distillation Techniques: The framework ensures that the classification results across modalities are consistent, with predictions from one modality guiding those from the other.
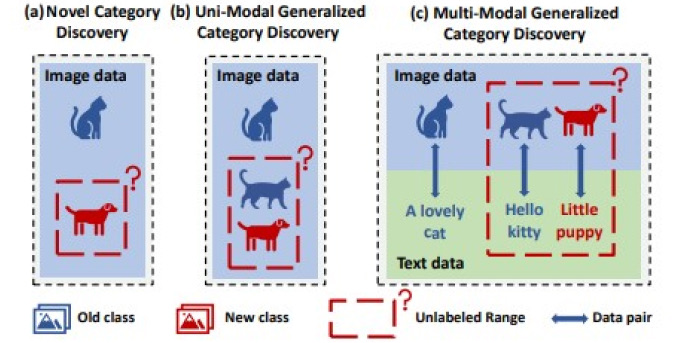
Problem Formulation – Classifying Known and Unknown Categories
The primary task for MM-GCD is to classify both known and unknown categories from multimodal data. This is especially useful in open-world settings, such as e-commerce or healthcare, where new data categories emerge frequently.
Problem Breakdown
- Labeled Dataset (DL)): This dataset contains known categories with corresponding labels. For example, an image of a dog and a matching textual description.
- Unlabeled Dataset (DU): This dataset contains both known and unknown categories, but the labels are unavailable. The model’s goal is to discover new categories while retaining accuracy for the known ones.
The MM-GCD model learns a function f(x) that maps the multimodal input space X=X1×X2 (where X1 represents image data and X2 represents text data) to the correct label, either from the known categories Yold or from the unknown categories Ynew.
Theoretical Analysis: Aligning Multimodal Data
Su et al. found that simply concatenating features from different modalities degrades model performance. Misaligned information between text and images can dilute valuable insights from each source. To address this, MM-GCD introduces a novel approach to align feature spaces, minimizing noise and improving classification accuracy.
Key Formulas:
Multivariate Normal Distribution: MM-GCD assumes that features from different modalities follow a multivariate normal distribution:
![]()
where μXk and μYk represent the means, and ΣXk, ΣYk are the covariance matrices for each modality.
Fused Modality: The two modalities are combined into a new feature space, ensuring proper alignment:
![]()
This fusion ensures the model maximizes the complementary strengths of text and image data.
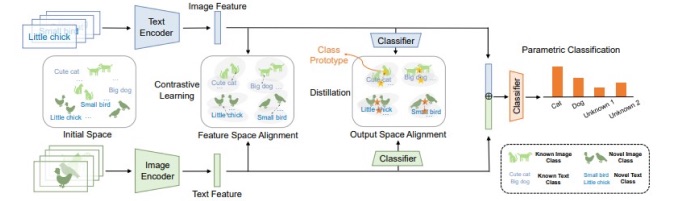
Method: Learning with Contrastive and Distillation Techniques
MM-GCD’s success relies on a two-step learning process:
Feature Space Alignment: To extract meaningful relationships between different modalities, MM-GCD leverages contrastive learning. This method aligns similar features from various data types closer together while distancing irrelevant ones. Imagine pairing an image of a “dog” with its description “a playful puppy”—the framework learns to recognize these as belonging to the same category.
Output Space Alignment: After aligning the feature space, MM-GCD uses distillation techniques to ensure that classification decisions are consistent across both modalities. This helps avoid misclassification that may arise due to differences in modality-specific features (e.g., a blurry image or a poorly written description). The output of one modality (like image) serves as a reference to guide classification in the other modality (like text).
Positive Pair Construction:
- Labeled Positive Pairs: Fully labeled instances, such as both an image and a description, are used to fine-tune the model’s alignment across modalities.
- Unlabeled Positive Pairs: Only one modality (e.g., text) is labeled, and the other is inferred, improving generalization in semi-supervised scenarios.
Results: Benchmark Performance
MM-GCD outperformed existing methods, setting new records on key benchmarks like UPMC-Food101 and N24News. By leveraging multimodal data, the framework achieved an 11.5% improvement in accuracy on the UPMC-Food101 dataset and a 4.7% boost on N24News.
Key Results
MM-GCD has demonstrated its effectiveness in major benchmarks like UPMC-Food101 and N24News, surpassing previous state-of-the-art performance by up to 11.5%. These successes highlight the transformative potential of multimodal learning across various sectors.
Food Classification (UPMC-Food101 Dataset): By analyzing both images of dishes and their associated text descriptions (ingredients, recipes), MM-GCD achieved a significant improvement in recognizing both common and novel food categories. Imagine this being extended to automated meal planning services that generate personalized nutrition advice based on a user’s uploaded meal photos.
News Classification (N24News Dataset): With multimodal inputs such as headlines, images, and article bodies, MM-GCD drastically improved the ability to detect not just common news topics but also emerging stories, which could be particularly useful for trend prediction in media and finance.
Ablation studies confirmed that without the feature and output alignment strategies, performance dropped by 18.8%, underscoring the importance of these techniques.
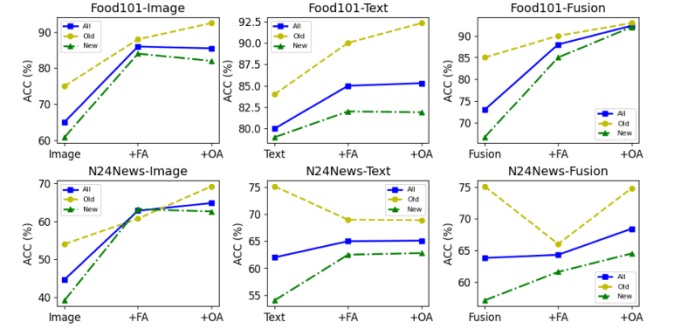
Ablation studies confirmed that without the feature and output alignment strategies, performance dropped by 18.8%, underscoring the importance of these techniques.
Why is Multimodal Learning Crucial for Generative AI?
AI systems that operate only within one modality are inherently limited. In the real world, information is multimodal by nature: a news article is accompanied by pictures, a social media post has both text and video, and a medical diagnosis might involve both lab reports and X-rays. By learning from multiple modalities simultaneously, MM-GCD enhances the AI’s understanding of complex, layered datasets.
Examples:
Healthcare: Radiology often involves analyzing medical images (X-rays, MRI scans) alongside doctor’s reports. A multimodal system that can correlate these could identify previously undetected patterns, speeding up diagnostics and improving accuracy.
Entertainment: Think of a video streaming service like Netflix. Multimodal AI can assess both visual features (e.g., scenes, lighting) and textual elements (e.g., dialogue, plot descriptions) to provide highly personalized recommendations.
E-Commerce: When browsing products online, customers are influenced by both product images and reviews. A multimodal generative model could better predict preferences by synthesizing these forms of data, enabling more accurate suggestions and even automatically generating product descriptions tailored to a user’s interests.
Impact on Future AI Systems
The integration of multimodal data into AI systems is not just an incremental upgrade—it’s a fundamental shift. As MM-GCD paves the way for enhanced learning from richer, more diverse datasets, we could see a wave of innovations in domains like virtual assistants, autonomous vehicles, and even scientific research.
Personal Assistants: Future assistants like Siri or Google Assistant will no longer rely purely on voice or text commands. By incorporating images, location data, and even real-time environmental context, they will offer more accurate and personalized responses.
Autonomous Vehicles: Self-driving cars could leverage multimodal inputs—combining visual data from cameras with LIDAR, radar, and map data. This would lead to more robust and safer navigation in complex environments, such as during adverse weather conditions.
Scientific Discovery: In the realm of rare diseases, MM-GCD could analyze multimodal datasets involving genetic data, clinical reports, and medical imaging to discover new disease variants, significantly accelerating research.
Future Challenges and Opportunities
While MM-GCD represents a significant advancement, challenges remain. One key issue is modality alignment, where inconsistencies between the quality of text and images can still confuse the model. Additionally, the sheer computational complexity of processing multimodal data requires further optimization. Nonetheless, as machine learning architectures continue to evolve, the future of generative AI promises systems that can think, understand, and create in a truly multimodal world.
The Next Frontier of AI
In conclusion, the research behind MM-GCD offers a promising glimpse into the future of multimodal systems in generative AI. By learning from diverse data types and aligning their insights, these models push the boundaries of what AI can achieve. Whether in healthcare, entertainment, or everyday technology, multimodal AI will play a key role in shaping a smarter, more intuitive digital world.
Frequently Asked Questions (FAQs)
What is the key innovation of MM-GCD?
MM-GCD extends Generalized Category Discovery (GCD) by incorporating multimodal data (e.g., images and text), allowing the model to classify both known and unknown categories across modalities, ensuring better performance in real-world, data-rich environments.
How does MM-GCD align multimodal data effectively?
MM-GCD employs contrastive learning for aligning features from different modalities (e.g., images and text) and distillation techniques to ensure consistency in output across modalities, improving classification accuracy.
What are some real-world applications of MM-GCD?
MM-GCD can be applied in healthcare for diagnosing diseases using medical images and clinical reports, in e-commerce for discovering new product trends, and in autonomous vehicles for combining data from sensors and cameras for better decision-making.
What datasets were used to test MM-GCD?
MM-GCD was tested on benchmark datasets like UPMC-Food101 and N24News, where it showed state-of-the-art performance, improving classification accuracy by 11.5% and 4.7%, respectively.
What are the future directions for MM-GCD research?
Future research could focus on integrating additional modalities (e.g., audio and video), applying MM-GCD in real-time applications like augmented reality, and expanding its use in new domains such as finance and scientific research.
Reference
The images, diagrams, and core content discussed in this article are referenced from the original research paper “Multimodal Generalized Category Discovery” by Yuchang Su, Renping Zhou, Siyu Huang, Xingjian Li, Tianyang Wang, Ziyue Wang, and Min Xu, 2024.

Director | AI Strategy, Innovation